


在开发自动驾驶汽车的激烈竞争中,激光雷达已成为最关键的硬件组件之一。激光雷达系统生成精确的点云数据,作为周围环境的3D地图,以提高自动驾驶汽车的感知能力和安全性。然而,对于AI研究人员而言,激光雷达点云语义分割仍然是一大挑战。
(图片来源:syncedreview.com)
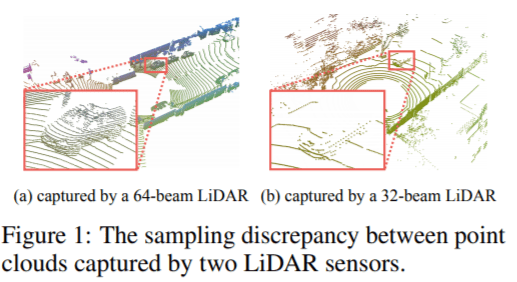
标注3D点云的缺乏阻碍了语义分割任务中深度神经网络性能的进一步提高。尽管一些自动驾驶公司发布了一些数据集,但激光雷达传感器的配置不同和其他域的差异导致了这一问题:在一个数据集上训练的深度网络在其他数据集上表现不佳。据外媒报道,为了弥补激光雷达传感器中3D点云采样差异造成的域差距,谷歌研究团队提出了一种新的“补全和标注”域适应方法,即激光雷达点云语义分割域适应方法(A Domain Adaptation Approach to Semantic Segmentation of LiDAR Point Clouds)。
研究人员发现了关键的一点:激光雷达样本具备底层几何结构,运用利用这些结构的3D模型,域适应可以更为有效。该团队假设了一个由3D表面组成的物理世界,并将域适应挑战作为3D表面补全任务。
研究人员表示,“如果我们可以从稀疏的激光雷达点样本中恢复完整的3D底层表面,并训练在补全后的表面上运行的网络,这样就可以利用激光雷达扫描仪的标注数据来处理其他数据。”该团队设计了一个稀疏体素补全网络(SVCN)来补全稀疏点云的3D表面。该网络结构包括两个阶段:表面补全和语义标注。与语义标注不同,获取SVCN训练配对不需要人工标注,因为表面补全可以从自我监督中学习。
该团队在根据多个激光雷达数据帧重建的完整表面的监督下,对补全网络进行训练。这些激光雷达帧包含2400个可用于训练的完整场景点云,200个可用于测试的点云。一旦3D表面被恢复,研究人员使用稀疏卷积U-Net来预测完整表面上每个体素的语义标签。在3D计算机图形学中,体素是定义3D空间中点的图形信息单位。
该团队通过使用不同的自动驾驶数据集进行实验,评估域适应新方法的有效性。实验结果显示,与此前的域适应方法相比,该方法的性能提高了8.2- 36.6%。例如,利用该方法,在Waymo开放数据集上训练的网络在nuScenes数据集上执行语义分割任务的平均IoU(Intersection-Over-Union,交并比)) 提高了10.4%,IoU是语义分割中最常用的度量指标之一。
该域自适应方案旨在填补激光雷达传感器3D点云的域差异,其提升语义分割性能的能力对于自动驾驶、语义映射和施工现场监控等应用具有巨大潜力。