


据外媒报道,日前,Facebook发布了三款新工具,SoundSpaces、 Semantic MapNet, 以及一个探索模型,帮助AI将学习如何规划路线、观察周围的物理环境、倾听正在发生的事情,以及构建3D空间记忆。
(图片来源:venturebeat.com)
“具身AI”(embodied AI )这一概念来源于“具身认知”(embodied cognition),该理论认为,心理学的许多特征都是由有机体整个身体的各个方面塑造的。研究人员将这一逻辑应用到AI中,旨在提高AI系统的性能,如聊天机器人、机器人、自动驾驶汽车,甚至是与环境、人以及其他AI进行交互的智能扬声器。例如,具身机器人可以检查一扇门是否上锁,或者取回楼上卧室里正在响铃的智能手机。Facebook表示,“通过推进这些相关研究,并与更广泛的AI社区分享我们的工作,我们希望加快构建具身AI系统和AI助手,帮助人们在现实世界中完成各种复杂的任务。”
虽然视觉是感知的基础,但声音也同样重要。声音能捕捉丰富的信息,这些信息通常难以通过视觉或力的数据察觉,比如干叶子的纹理或香槟瓶内的压力。但很少有系统和算法利用声音作为构建物理理解的工具,因此Facebook发布了SoundSpaces。
SoundSpaces是一个基于3D环境声学模拟的音频渲染语料库。该数据集旨在与Facebook的开源模拟平台AI Habitat一起使用,提供软件传感器,使其可以在扫描的真实环境中插入模拟声源。
SoundSpaces与卡耐基梅隆大学一个团队的工作有一定关联,该团队发布了“声音-动作-视觉”数据集和一系列AI算法,以研究声音、视觉和运动之间的相互作用。该团队称,研究结果表明,声音再现可用于预测物体受到物理力量时的移动方向。
但Facebook表示,与卡耐基梅隆大学的研究不同,创建SoundSpaces需要声学建模算法和双向路径追踪组件模拟空间中的声音反射。由于材料会影响环境中接收到的声音,如在大理石地板上而不是地毯上行走,因此SoundSpaces还试图复制墙壁等表面的声音传播。同时,SoundSpaces还允许渲染位于主流数据集(如Matterport3D和Replica)环境中多个位置的并发声源。
此外,SoundSpaces还引入了AI训练方法AudioGoal,即AI主体必须在环境中移动,以找发出声音的物体。AudioGoal训练AI在不熟悉的环境中,利用视觉和听觉定位可听到的目标物体。Facebook称,与传统方法相比,AudioGoal能加快训练速度,提高导航精度。Facebook还表示,“AudioGoal 主体不需要目标位置指示,因此主体可利用多模态传感发现目标位置。我们经过学习的音频编码提供与GPS类似,甚至比GPS位移更好的空间线索。这表明音频可提供对GPS噪声的抗干扰能力。”
Facebook还发布了Semantic MapNet,该模块使用空间语义记忆形式记录物体在探索周围环境时的图像。Facebook称,这些空间图像为完成一系列具身任务提供了基础,包括导航到特定位置和回答问题。
Semantic MapNet可以预测特定物体位于其绘制的像素级、自上而下的地图中的位置。MapNet构建所谓的“非自我中心的”记忆,这是一种助记表示,可以捕获物体之间与视图无关的关系,以及物体与环境之间的固定关系。Semantic MapNet从观察中提取视觉特征,然后使用端到端框架将其投射到某个位置,利用所看到物体的标注,解析自上而下的环境地图。
该项技术使Semantic MapNet能够分割可能从鸟瞰图看不到的较小物体。项目步骤还允许Semantic MapNet对给定点及其周围区域的多个观测进行推理。Facebook表示,“这些构建神经情景记忆和空间语义表征的能力,对于改进自动导航、移动操作和以自我为中心的个人AI助手而言非常重要。”
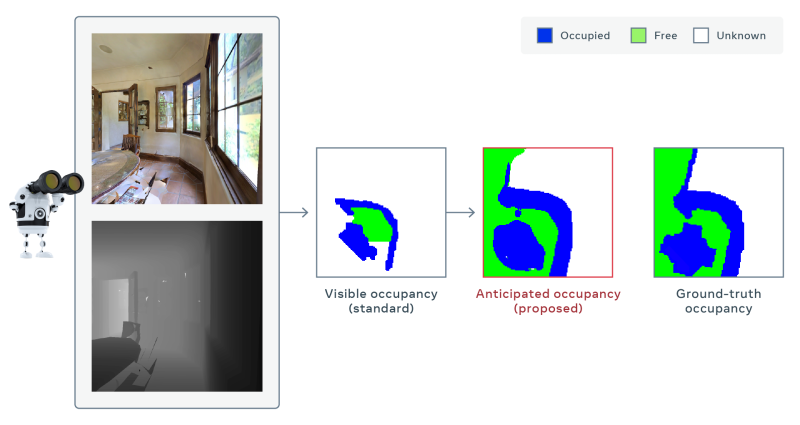
此外,Facebook还开发了一种模型,可以推断环境地图中无法直接观察到的部分,如餐厅的桌子后面。该模型根据静态图像帧预测占用率,即物体是否存在,并且随着时间的推移,在其学习导航的过程中,将这些预测汇总起来。Facebook表示,其模型在仅使用三分之一的移动次数的情况下,将地图精度提高了30%,优于最佳竞争方法。在今年的计算机视觉和模式识别大会上,该模型还获得了一项任务的第一名,该任务要求系统适应较差的图像质量,并在没有GPS或指南针数据的情况下运行。
该模型仅在模拟中部署,尚未部署到真实的机器人中。但Facebook希望,当与其支持LoCoBot等机器人的机器人框架PyRobot一起使用时,该模型可以加速具身AI领域的研究。