


已整理完毕. 禁止转载.
(本回答不涉及GPU, GPU评比请参看notebookcheck提供的GPU天梯:
notebookcheck.net/Intel-HD-Graphics-4600.86106.0.html
)
以下为Intel提供性能提升数字:
(2013)Hawell相对于Ivy Bridge, 8%矢量处理性能提升, 6%单线程性能提升, 6%多线程性能提升, 3%总体性能提升.
(2012)Ivy Bridge相对于Sandy Bridge, 3-6%同频性能提升.
(2011)Sandy Bridge相对于Westmere, 11.3%同频性能提升.
(2010)Westmere相对于Nehalem, 因为Westmere本就是Nehalem-C, 所以同频性能相同.
(2008)Nahelm相对于Penryn, 10-25%单线程性能提升, 20-100%多线程性能提升, 15-20%同频性能提升
可以看到从第一代Core商标(Nehalem架构)到第四代Core商标(Haswell架构), Intel处理器的性能提升越来越小. 但是Intel其实重点提升了处理器的多线程计算能力. 下面是我整理的Intel近几代处理器性能对比, 是从Spec2006官网海量数据里挑选出来的. (引用:
SPEC CPU2006
)
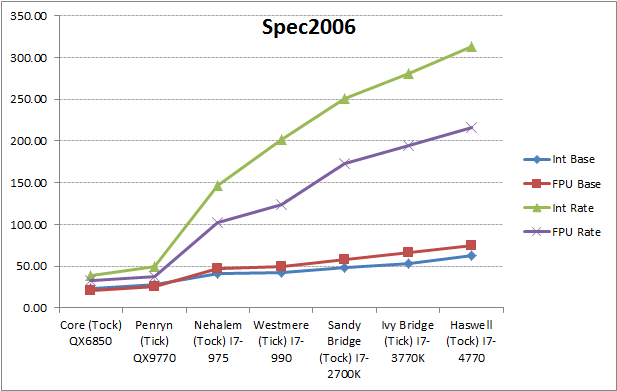
(注: 这里使用了Intel桌面Extreme版处理器做测试对象, 它代表了桌面处理器的最高性能)
(注: rate测试分数有改动, 原因是手边没有SB, IB, Haswell的I7-EE版CPU数据, 直接使用了普通版I7做了等效)
从上往下:
绿色:整形多线程分数 (Rate)
紫色:浮点多线程分数 (Rate)
蓝色:整形单线程分数 (base)

紫色:浮点单线程分数 (base)
图中横坐标:
(请注意这里有Core架构和Core商标的区别.)
从图中可以看到, Intel处理器的多线程运算能力一直在稳定上升, 上升幅度超过单线程幅度.
单线程Spec2006项目每代上升幅度在15%左右, 多线程上升幅度在30%左右. 如今, 多线程运算能力真正代表处理器的性能.
下面来分析这30%多线程性能的上升:
多线程提升要依次考虑到这4个方面: 1. 线程数, 2. 主频, 3. 编译器, 4. 核心架构.
这里可以看出, Core系列处理器架构的改进并不是最重要的, 工艺才是对处理器性能提升最重要的关键因素. 因为工艺决定了处理器的核心数量, 主频, 甚至包括架构细节.
参与分析的CPU具体参数如下:
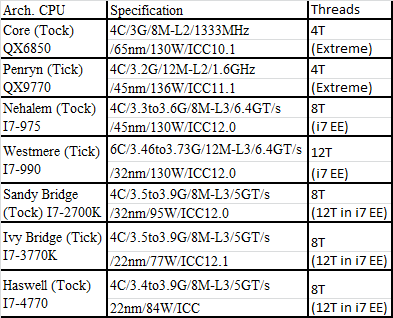
(注, SB, IB, Haswell三项在作图时已经等效为6C/12T处理器分数)
以下分别从之前提到的4个方面来描述历代处理器的区别:
1. 线程
在Core架构时代(最多4线程)到Westmere(最多12线程), 而这段时间Spec2006 Rate项分数变在4倍以上. 从Westermere开始, Intel维持了12线程的数目, 之后的3代产品中, rate分数仅上升了1倍. 可以看出CPU支持的线程数量是最影响处理器性能的因素.
性能的飞跃是从Intel在桌面处理器上使用了Hyper Threading(超线程)技术开始的, Intel认为"单物理核心, 双线程"这样的技术等效为1.4个物理核心的性能. 这个技术最早用在了Netburst架构(Pentium4)上, 但是并没有在Core架构上使用, 直到Nehalem架构上, Intel又重拾HT, 使得Nehalem这一代处理器的性能远远超出上一代Penryn产品. Intel也是在这个时候开始使用酷睿(core)i3/i5/i7这个系列名称的.
2. 主频
在Core架构时代, 由于刚刚走出Netburst(Pentium4)的阴霾, 采用新的架构, Intel并没有急于提升主频, 即便是Extreme版桌面处理器QX6850, 主频也仅3G.
在Nehalem架构上, Intel开始提升处理器主频, 直到Sandy Bridge架构时, 主频已经可以达到3.5G. 这对于Sandy Bridge这样仅有14级流水线的架构来说是非常惊人的! (对比Pentium4, 虽然P4早就到过4G以上的主频, 但是有近30级的流水线.)
此外, 在Nehalem架构上, Intel采用了Turbo技术, 结合处理器负载量, 处理器温度等信息, 动态调整处理器主频, 最高主频达到了3.9G, 非常夸张, 这需要架构和制程的共同配合才能做到.

3. 编译器
Intel C++ Compiler (ICC说明:
Intel C++ Compiler
)
伴随着自家处理器的更新换代, Intel总会及时更新ICC编译器, 以方便软件针对Intel不同的处理器进行优化. ICC会使用CPUID这个指令, 它可以返回处理器支持的指令集种类, 方便ICC根据具体CPU型号, 输出优化后汇编指令. (新版的指令集需要配合新版的ICC编译使用.)
举个栗子: Nehalem架构处理器使用不同版本的ICC得分:

可以看到, ICC不同版本对Spec2006成绩有很大影响. 这是因为使用ICC11编译的程序无法使用较新指令集. (如SSE4.2)
下面列举了Intel历代产品所添加的新指令/指令集, 这些指令均可被当时最新的ICC支持:

这里简单分成两类, 加粗的指令集可以加快CPU计算速度. 未加粗的为CPU功能拓展, 转换, 辅助类.
这里也解释了为什么有时Intel官方宣传性能上升~8%, 但是Spec2006的分数却上升接近15%. 原因就是ICC针对了最新的处理器/指令集做过优化, 像Spec2006这样的重要测试是需要重点优化的.
4. 架构
为了能直观的比较架构差别, 这里先把Spec2006单线程测试(base)针对主频做了归一化. 结果如下:
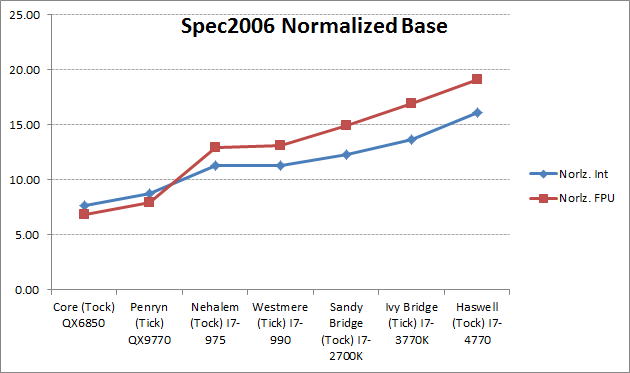
对比结果如下: (第二, 三列为: 针对上一代产品, 新架构的提升百分比. 第二列为整型测试, 第三列为浮点型测试)
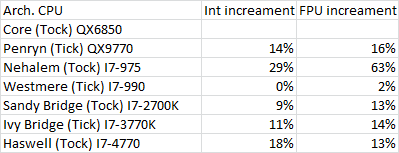
(注: 提升百分比包含ICC编译器升级带来的变化)
下面列出架构间的变化, 方便大家对比查看.

4.1 Nehalem
Core的x86解码能力是每周期4个, Nehalem相同.
Core的Loop Cache是18层, Nehalem应有增加, 数量未知.
Core有16层返回栈缓存, Nehalem相同.
Core的分支预测机制能提前32Byte进行预测, Nehalem相同, 而且增强了预测算法, 并加快了预测错后重新取指速度.
Core有6个执行单元, Nehalem相同.
Core的保留站有32层, Nehalem增加至36层.
Core的乱序执行窗口长96层, Nehalem增加至128层.
Core每周期可以进行128bit读和128bit写, Nehalem相同.
Core的读缓存24层(猜测), Nehalem增加至48层.
Core的写缓存20层, Nehalem增加至32层.
Core的L1I 32k(4-way), L1D 32k(8-way), Nehalem相同
Core没有SLC, Nehalem的L2 256k(8-way).
Core的L3 4M(8-way), Nehalem 8M, 且延迟是core的1/3.
Core的TLB为L0D 16层, L1D 256层, Nehalem的L1I 64层, L1D 64层, L2 512层.
此外, Nehalem还增强了批量读写的算法, 增加了融合覆盖的范围.
4.2 Sandy Bridge
Nehalem的x86解码能力是每周期4个, SB相同.
Nehalem解码遇到变长前缀时, 有6周期惩罚, SB只有3周期.

Nehamle使用传统解码方式, SB使用的2次解码, 第二次利用微码队列(56层)来完成.
Nehalem有6个执行单元, SB相同.
Nehalem的保留站有36层, SB推测为48层.
Nehalem的乱序执行窗口128层, SB增加为168层.
Nehalem每周期可以进行128bit读和128bit写, SB增加为256bit读和128bit写.
Nehalem的读缓存48层, SB增加为64层.
Nehalem的写缓存32层, SB增加为36层.
Nehalem的L1I 32k(4-way), L1D 32k(8-way), SB的L1I和L1D均为 32k(8-way).
Nehalem的L2 256k(8-way), SB相同, 但延迟稍大些.
Nehalem的L3 8M, SB相同, 且延迟是Nehalem的2/3.
Nehalem的TLB为L1I 64层, L1D 64层, L2 512层, SB的L1I 128层, L1D, L2与Nehalem相同. Haswell的L2 1024层.
SB在Nehalem的基础上, 再次增强了分支预测的算法.
SB使用了类似Pentium4的Decoded Icache, 但仍然保留了L1 ICache, Decoded ICache可以保存1506条微码, 提升了解码带宽, 降低了分支预测错误的惩罚.
SB使用了改进后的预取策略, 预取的成功率提升很大, 有效降低了Cache Miss几率.
SB优化了执行单元的结构, 使得读写延迟减小, 写回冲突减少,数据前递延迟减少i7, FPU异常解决速度加快.
SB启用了非常关键的Ring Bus结构, 并将CPU上升为Soc, 集成了System Agent, Memory Controller,PCIe Controlleri7, GPU等.
4.3 Haswell (资料不足, 仅列关键数据)
SB的x86解码能力是每周期4个, Haswell相同.
SB的Loop Cache推测在40层左右, Haswell增加至56层.

SB有6个执行单元, Haswell增加至8个.
SB的保留站推测为48层, Haswell增加至60层.
SB的乱序执行窗口为168层, Haswell增加至192层.
SB每周期可以进行256bit读和128bit写, Haswell增加至256bit读和256bit写.
SB的L1I和L1D均为32k(8-way), Haswell相同.
SB的L2 256k(8-way), Haswell相同.
SB的L3 8M, Hawell相同.
SB的TLB为L1I 128层, L1D 64层, L2 512层, Haswell的L1I, L1D与SB相同, Haswell的L2 1024层.
基本可以看出来, 在CPU架构上, Intel这几年基本没有改动流水线结构, 而是通过增加CPU内部带宽, 增加CPU内部队列深度等暴力手段来获得性能提升. 同时, Intel非常注重提升多线程运算能力和并行计算能力, 许多CPU的改进都是为了大量数据移动/计算而设计的. 比如增强Rep前缀速度, 加快Shuffle/Blend算法等.
由于Intel手握世界上最先进的制程, 很多改进的实质都是以面积换速度, 比如Decoded ICache这样的功能. 所以可以大胆预测, 只要Intel的制程还在进步, Intel未来CPU架构里还会加入更多新功能.
结束语:
性能并非是个可以量化分析的数字, 对于CPU来说, 广义的"性能"过于依赖使用环境. 科学计算十分依赖线程数和计算力峰值. 日常使用依赖于整个主机系统的短板项. 游戏往往不过分看重CPU的能力.
而狭义的"性能"则好说许多, 即是各种主流benchmark的跑分分数. 不过讽刺的是, benchmark的选择却又依赖于使用环境. 有的测试计算能力, 比如算pi值,质数, 象棋的benchmark. 有的测试日常使用, 比如windows自带的Windows Experience Index. 有的测试游戏性能, 比如3Dmark.
那选择什么样的benchmark能代表CPU性能呢?
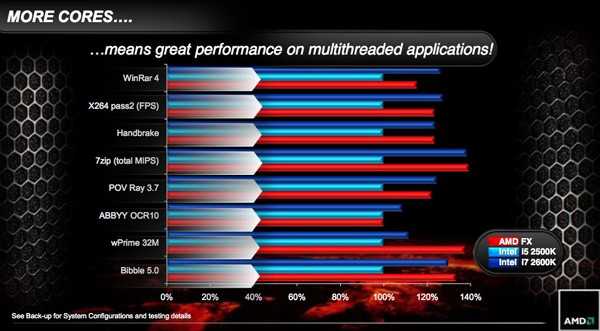
(这是2011年, AMD FX系列处理器发布会上选用的benchmark, 由于架构上有不足, 很多主流benchmark表现并不理想, 因此在自家的广告上, 甚至不得不请些少见的benchmark项来凑数. )
对于上面的问题, 实际的解决方法是还得按市场的需求来. 即, 以市场认同, 有权威性的benchmark为准. 诸如PCMark, CrystalMark, Cinebench, 3DMark, 7Zip, Aida64等等. 这样做即方便量化分析CPU性能, 又可以准确的向消费者传达自家CPU产品的销售定位.
本回答提到的Spec系列测试, 可以说是测评领域中最重要的测试. 测试内容包括gcc, perl, zip, xml以及大型科学计算如流体力学,语音识别,材料物理等. 但它也有明显的缺点, spec没有大量的访存测试, 没有模拟普通用户行为, 这与实际使用有不少区别.
可以看到, "性能评估"其实没有标准答案. 许多科技网站会做大量CPU评测, 可是仅仅通过分数并不能判断CPU架构优劣的. 要考虑评测的分数是不是线性, 评测软件是否针对每一款CPU都优化到位, 评测软件代码也许过于机械或脱离实际, 这样的问题.
如今我们提到"性能", 其实更多想表达的是整个系统的性能. 内存大小, 硬盘速度, 外设协议, 甚至OS好不好, 这些都远远大于CPU快或慢带给用户的感受. 真正的CPU性能, 已经变得越发朦胧了.